
全球最大,马斯克4个月建成10万张H100超算集群!xAI算力逾越OpenAI,奥特曼怕了
编者按:本文来自微信大众号 新智元(ID:AI_era),修改:修改部,创业邦经授权转载。
马斯克的xAI一路狂飙突进,把Sam Altman都整怕了!
就在9月3日,马斯克在推上满意自曝:
团队仅仅用了122天时刻,就建成了有10万张H100的Colossus集群,是世界上最强壮的AI练习体系。
并且,未来几个月规划还要翻一倍,扩展到15万张H100+5万张H200。

现在看来,这些集群很或许都正式投入运转,乃至现已在练习AI模型了。
不过,马斯克真的有才干让它们悉数在线吗?
首要问题是,要调试和优化这些集群的设置,需求必定时刻。
其次,xAI还得确保它们取得满意的电力。
咱们知道,尽管马斯克的公司一贯在用14台独立发电机为其供电,但要为十万块H100 GPU供电,这些电力明显不行。
练习xAI的Grok 2,需求两万块H100;而马斯克猜想,要练习Grok 3,或许会需求十万块H100。
所以,xAI的数据中心,建得怎样巨大都不过火。
制作速度太快,估测是「部分上线」
122天,也便是4个月的时刻,建成10万张H100组成的超算集群,这是个什么速度?
有业界人士表明,一般完结这样一个集群或许需求一年时刻。
这个速度,这个规划,很马斯克。

其间一位,便是OpenAI的CEO Sam Altman。
依据内部音讯,奥特曼现已向一些微软高管泄漏了自己的忧虑——
他十分忧虑,xAI很快就具有比OpenAI更多的算力!

并且,The Information还发现了一个「华点」:Colossus坐落曾经的制作工厂内,这可不是合适高性能核算的抱负场所。
微柔和英伟达的高管泄漏,这是他们最不乐意放置贵重硬件的地址之一。
由于这些当地很难改造,来习惯服务器消耗的巨大电量,和数据中心设备需求的冷却技能。
咱们都知道,马老板一贯喜爱打破鸿沟,而在质疑声接连不断时,他又经常被证明是正确的。
最近在xAI的姊妹公司X,马斯克又有了一个惊人之举:封闭了一个数据中心。
其时咱们都忧虑,X会因而而溃散。成果谁也没想到,X运转得很好,马斯克居然有如此先见之明。
而这次,马斯克在田纳西州的超算,也相同或许会对AI开发者振聋发聩——
或许他们会发现,传统的干事方法现在现已过期了。
两家奥秘AI巨子,正方案打造1250亿美元超算
现在,数据中心之战,比赛还在炽热加重!至少有六大巨子,现已下场了。
依据北达科他州官员的宣布,除了微软、OpenAI和xAI,还有两家AI巨子也正在酝酿制作「巨型AI数据中心」。

这两家公司找到了商务专员Josh Teigen和州长Doug Burgum,参议树立巨型AI数据中心。
除了技能研制,这类数据中心也对资源和基础设备提出了很高的要求。
不只需求收购满意的芯片和相关设备,还要留出数万英亩的土地、制作新的发电设备。
马斯克的Colossus要自建发电站才干弄出200兆瓦,而这两家公司或许是由于直接找上了州长,他们的初始电力就能到达500~1000兆瓦,并方案在几年内扩增至5k~1w兆瓦。
这些项目的规划将比现有的任何数据中心,包括Colossus都扩展几个数量级。
100兆瓦能够为7万至10万个家庭供电;上一年微软Azure的全球数据中心一共运用了大约5吉瓦(5k兆瓦)的电力。
这就意味着,一个数据中心,或许和整个Azure云服务渠道的耗电量适当。
依据会议的音频记载,这类规划的项目耗资或许超越1250亿美元。
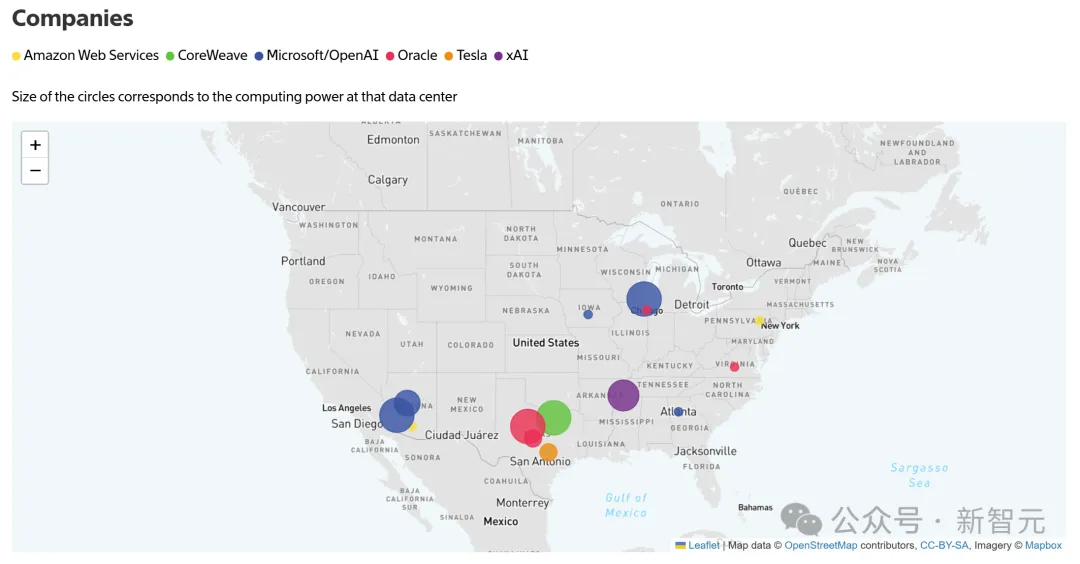
这些超算估量在数年时刻内完工,并需求许多的芯片、土地和电力。
在ChatGPT面世前,GPU集群一般只包括几千个芯片。现在,一些最大的GPU集群具有超越3万个芯片,上面说到的这些超算更是到达了史无前例的规划。
要为一切方案中的数据中心供电,美国动力部估计会呈现电力缺乏的状况,因而最近提出了一些解决方案,例如赞助研讨使AI核算更高效。

抢夺「下一个高地」
现在,数据中心比赛的焦点,会集到了英伟达CEO黄仁勋的身上。
就在上星期,老黄宣布了以下言辞,宛如在业界投入一颗炸弹。
首先到达超算集群下一个高地的人,将完结革命性的AI水平。
此言一出,英伟达的GPU,谁敢不买?
即便现已和博通一起规划出了TPU的谷歌,最近也为英伟达行将推出的Blackwell下了大单。

对GPU的抢夺,现已引发了AI开发者及其云供货商之间的紧张局势,乃至,有时还会引发它们和英伟达的冲突。
比方,马斯克就曾考虑和甲骨文达到一项大规划协议,依据他的方案,xAI将在未来几年内,花费超越100亿美元租借英伟达的GPU。
而这项商洽终究破裂了,部分原因在于,马斯克认为甲骨文无法满意快地建起超算,而甲骨文则忧虑,他会把GPU集群放在一个供电缺乏的当地。
芯片多多,问题多多
许多超大的GPU集群都坐落土地广阔、空间富余且电力足够的区域。例如,马斯克的Colossus特意选址在田纳西州孟菲斯,亚马逊、Meta和微软都在亚利桑那州的凤凰城区域运营AI服务器。
但随着更大的GPU集群需求更多的电力,AI巨子们正方案在非传统数据中心纽带的区域制作这些集群。
例如,亚马逊最近在宾夕法尼亚州中部的一座核电站周围置办了土地,方案供给约一吉瓦(1000兆瓦)的电力。
这足认为整个旧金山供电,或许构建多达100万张GPU的集群。
另一个应战是怎么进行设备冷却。
传统上,数据中心一般选用风冷,但GPU服务器发生的热量远远超越传统服务器。
为了更佳的冷却作用,微软在威斯康星州为OpenAI制作的数据中心估计将运用液冷而非风冷。
尽管现在越来越多人置疑,AI泡沫要挨近临界点了,但兴修超算之风,一时半会还不会冷却。
究竟,竞家都All In了,你能不上吗?
六巨子割据,群雄逐鹿,谁将夺得下一个超算高地?
参考资料:
https://www.theinformation.com/articles/why-musks-ai-rivals-are-alarmed-by-his-new-gpu-cluster?rc=epv9gi
https://www.tomshardware.com/tech-industry/artificial-intelligence/xai-colossus-supercomputer-with-100k-h100-gpus-comes-online-musk-lays-out-plans-to-double-gpu-count-to-200k-with-50k-h100-and-50k-h200
https://www.theinformation.com/articles/two-ai-developers-are-plotting-125-billion-supercomputers
https://www.theinformation.com/articles/introducing-the-ai-data-center-database?rc=epv9gi
本文为专栏作者授权创业邦宣布,版权归原作者一切。文章系作者个人观点,不代表创业邦态度,转载请联络原作者。如有任何疑问,请联络editor@cyzone.cn。

启动")


发表评论